More thoughts on Generative AI
I attended a roundtable organised by the #Singapore Academy of Law titled “Generative AI and the Impact on Law and Society”. Although they weren't able to end the seminar without talking about misinformation, I was glad that the technical detail (both on the engineering and legal level) were more advanced. I even heard the word of a Legal #GPT trained on the datasets of local legal materials.
This graph was shown during the seminar:
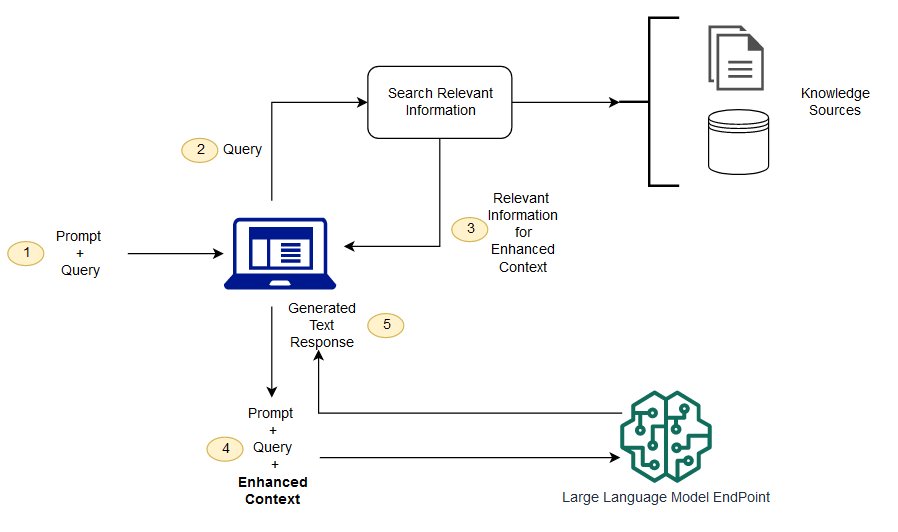 Source: https://aws.amazon.com/blogs/machine-learning/question-answering-using-retrieval-augmented-generation-with-foundation-models-in-amazon-sagemaker-jumpstart/
Source: https://aws.amazon.com/blogs/machine-learning/question-answering-using-retrieval-augmented-generation-with-foundation-models-in-amazon-sagemaker-jumpstart/
I suppose it was the hot thing for a long while, fueling endless extensions on #langchain trying to grab data from any plausible source, and graduating into plugins in #ChatGPT.
I've tried it myself and published my experiments on it.
Suffice to say, my opinion has soured “on the grab three relevant articles from my vector db and ask ChatGPT to write an answer on it”.
- It depends greatly on the makeup of your data store. What you don't have, the LLM can't answer correctly.
- The granularity of the embeddings made from your data store seems also to have a significant impact. An embedding that takes too wide or narrow a snapshot of your data might miss or jumble the point.
- Picking three points or whatever arbitrary number of custom content as a context was a problem created by the context window of the LLM. I am not sure how increasing it will improve the answer or how to get an optimum number of sections.
Mind you, these problems are not insurmountable. But it does say that there is a lot of room for improvement.
Augmented data retrieval is a great hobby project: it produces quick results with little investment, and it shows you know something.
But it also shows how far you can get with prompt engineering. This is after all a problem resolved by having a great prompt and a great foundational model. There's no fine-tuning or training.
The great promise of state-of-the-art models like GPT-4 is that their capability and accuracy are good enough that you don’t need to incur the costs of training or fine-tuning your custom model.
It might be cool to proclaim to your customers that you have a custom-made model for the #Singapore legal domain, although whether you achieved this by spending a lot on fine-tuning or prompt engineering is a curious question that might not be ultimately important.
Let's keep building!
#Law #ChatGPT #DataAugmentedRetrieval

- Discuss... this Post
- If you found this post useful, or like my work, a tip is always appreciated:

- Follow this blog on the Fediverse [Enter the blog's address in Mastodon's search accounts function]
- Contact me: