[Part 3] Do more with docassemble: Getting work done in a background action

Introduction
In Part 2, we managed to write a few questions and a result screen. Even with all that eye candy, you will notice that you can’t run this interview. There is no mandatory block, so docassemble does not know what it needs to do to run the interview. In this part, I will talk about the code block required to run the interview, forming the foundation of our next steps.
1. The backbone of this interview
In ordinary docassemble interviews, your endpoint is a template or a form. For this interview, the endpoint is a sound file. So let’s start with this code block. It tells the reader how the interview will run. Since it is a pretty important block, we should put it near the top of the interview file, maybe right under the meta block. (In this tutorial, the order of blocks does not affect how the interview will run. Or at least until you get to the bonus section.)
mandatory: True
code: |
tts_task
final_screen
If you recall, the user downloads the audio file in the final screen.
So this mandatory code block asks docassemble to “do” the tts_task and then show the final screen. Now we need to define tts_task, and your interview will be ready to run.
So what should tts_task be? The most straightforward answer is that it is the result of the API call to create the sound file. You can write a code block that gets and returns a sound file and assigns it to tts_task.
Well, don’t write that code block yet.
2. Introducing the background action
If you call an API on the other side of the internet, you should know that many things can happen along the way. For example, it takes time for your request to reach Google, then for Google to process it using its fancy robots, send the result back to your server, and then for your server to send it back to the user. In my experience, Google’s and docassemble’s latency is quite good, but it is still noticeable with large requests.
A user is not supposed to notice that a program lags when the interview runs well. If the user realises that the interview is stuck on the same page for too long, the user might get worried that the interview is broken. The truth is that we are waiting for the file to come back. Get back in your chair and wait for it!
To improve user experience, you should have a waiting screen where you tell the user to hold his horses. While this happens, the interview should work in the background. In this manner, your user is assured everything is well while your interview focuses on getting the file back from Google.
docassemble already provides a mechanism for the docassemble program to carry out background actions. It’s aptly called background_action().
Check out a sample of a background action by reading the first example block (”Return a value”) under the Background processes category. Modify our mandatory code block by following the mandatory code block in the example. It should look like this.
mandatory: True
code: |
tts_task
if tts_task.ready():
final_screen
else:
waiting_screen
So now we tell docassemble to do the tts_task, our background task. Once it is ready, show the final screen. If the task is not ready, show the waiting screen.
3. Define the background action
Now that we have defined the interview flow, it’s time to do the background action. In the spirit of docassemble, we do this by defining tts_task.
The next code block defines the task. Adapt this example into our interview file as follows.
code: |
tts_task = background_action(
'bg_task',
text_to_synthesize=text_to_synthesize,
voice=voice,
speaking_rate=speaking_rate,
pitch=pitch,
)
So we have defined tts_task as a background action. The background action function has two kinds of arguments.
The first positional argument (“bg_task”) is the name of the code block that the background action should execute in the background.
The other keyword arguments are the information you need to pass to this background action like the text_to_synthesize, voice etc. These options you answered earlier during this interview will now be used for this background action. Defining your variables here in a mandatory block indirectly also ensures that docassemble will look for the answers for these variables before performing this code block.
So why do you need to define all the variables in this way? Don’t forget that the background action is a separate process from the rest of your interview so they don’t share the same variables. To enable these processes to share their information, you pass on the variables from the main interview process to the background action.
4. Perform the background action
We have defined the background action. Now let’s code what happens inside the background action.
The background action is defined in an event called bg_task. Now add a new code block as follows:
event: bg_task
code: |
audio = get_text_to_speech(
action_argument('text_to_synthesize'),
action_argument('voice'),
action_argument('speaking_rate'),
action_argument('pitch'),
)
background_response()
So in this code block, we say that the audio is obtained by calling a function named get_text_to_speech. For get_text_to_speech to produce an audio file, it requires the answers to the questions you asked the user earlier. As a background process, it gets access to the variables you defined earlier through the keywords of the background_action function by calling action_argument.
Once get_text_to_speech is completed, we call background_response(). Calling background_response is important for a background action as it tells docassemble that this is the endpoint for the background action. Make sure you don’t leave your background action without it.
5. Provide a waiting screen
Before we leave the example block for background processes, let’s add the question block that tells the user to wait for their audio file. Find the block which defines waiting_screen, and adapt it for your interview as follows.
event: waiting_screen
question: |
Hang tight.
Google is doing its magic.
subquestion: |
This screen will reload every
few seconds until the file
is available.
reload: True
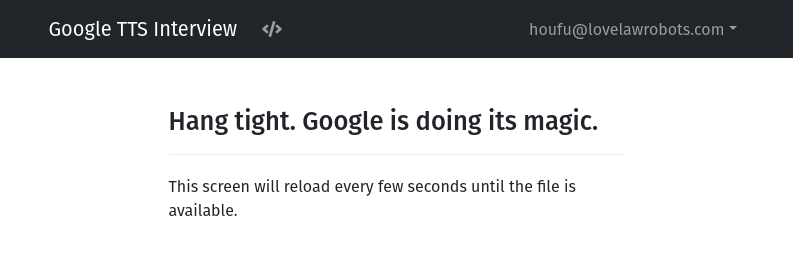
By adding reload: True to the block, you tell docassemble to refresh the screen every 10 seconds. This helps the user to believe that they only need to be patient and some “magic” is going on somewhere.
Conclusion
In the next part of the tutorial, we will dive into get_text_to_speech. (What else, right?) We will need to call Google’s Text-to-Speech API to do this. If you found it easy to follow the code blocks in this part of the tutorial, we will kick this up a notch — the next file we will be working on ends with a “.py”.
👈🏻 Check out the overview of this tutorial.
#tutorial #docassemble #Programming #Python #Google #TTS

- Discuss... this Post
- If you found this post useful, or like my work, a tip is always appreciated:

- Follow this blog on the Fediverse [Enter the blog's address in Mastodon's search accounts function]
- Contact me: