[Part 5] Do more with docassemble: Provide an audio file for your user to download 💾

Introduction
You must have worked hard to get here! We are almost at the end now.
Our journey took us from providing the user experience, figuring out what should happen in the background, and interacting with an external service.
In this part, we ask docassemble to provide a file for the user to download.
Provisioning a File
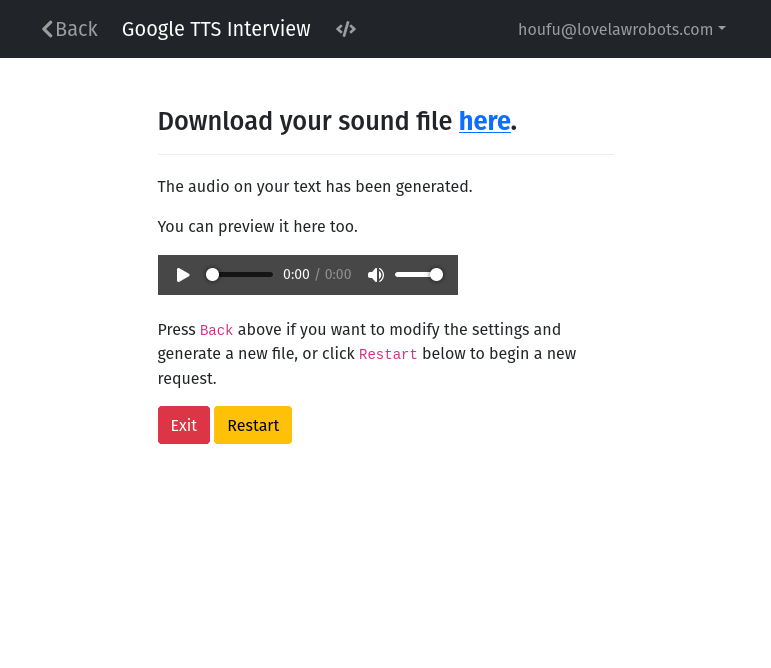
When we left part 2, this was our result screen.
event: final_screen
question: |
Download your sound file here.
subquestion: |
The audio on your text has been generated.
You can preview it here too.
<audio controls>
<source type="audio/mpeg">
Your browser does not support playing audio.
</audio>
Press `Back` above if you want to modify the settings and generate a new file,
or click `Restart` below to begin a new request.
buttons:
- Exit: exit
- Restart: restart
There are two places where you need an audio file.
- In the “question”, a link to the file is provided in “here” for download.
- The audio preview widget (the thing which you click to play) also needs a link to the file to function.
Luckily for us, docassemble provides a straightforward way to deal with files on the server. Simply stated, create a variable of type DAFile to hold a reference to the file, save the data to the file and then use it for those links in the results screen.
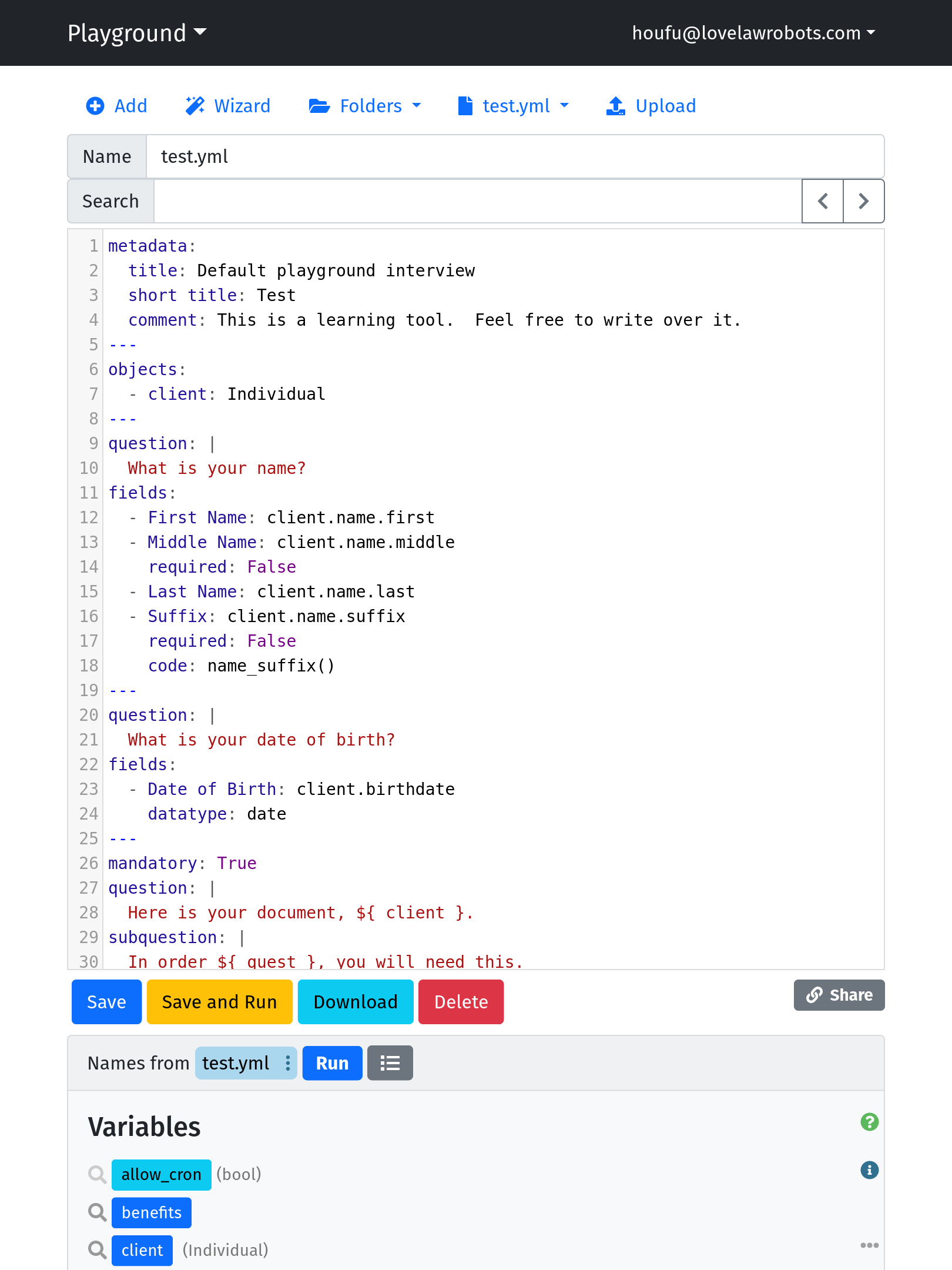
Let’s get started. Add this block to your main.yml file.
---
objects:
- generated: DAFile
---
This block creates an object called “generated”, which is a DAFile. Now your interview code can use “generated”.
Add the new line in the mandatory block we created in Part 2.
mandatory: True
code: |
# The next line is new
generated.initialize(filename="output.mp3")
tts_task
if tts_task.ready():
final_screen
else:
waiting_screen
This code initialises “generated” by getting the docassemble server to provision it. If you use “generated” before initialising it, docassemble raises an error. 👻 (You will only get this error if you use the DAFile to create a file)
Now your background action needs access to “generated”. Pass it in a keyword parameter in the background action you created in Part 3.
code: |
tts_task = background_action(
'bg_task',
text_to_synthesize=text_to_synthesize,
voice=voice,
speaking_rate=speaking_rate,
pitch=pitch,
# This is the new keyword parameter
file=generated
)
Now that your background action has the file, use it to save the audio content. Add the new lines below to bg_task that you also created in Part 3.
event: bg_task
code: |
audio = get_text_to_speech(
action_argument('text_to_synthesize'),
action_argument('voice'),
action_argument('speaking_rate'),
action_argument('pitch'),
)
# The next three lines are new
file_output = action_argument('file')
file_output.write(audio, binary=True)
file_output.commit()
background_response()
We assign the file to a new variable in the background task and then use it to write the audio (make sure it is in binary format as MP3s are not text). After that, commit the file to save it in the server or your external storage, depending on your configuration. (The above method are from DAFile. You can read more details about what they do and other methods here.)
Now that the file is ready, we can plunk it into our results screen. We are providing URLs here so that your user can download them from the browser. If you used paths, that would not work because it is the server's file system. Modify the lines in the results screen block.
event: final_screen
question: |
# Modify the next line
Download your sound file **[here](${generated.url_for(attachment=True)}).**
subquestion: |
The audio on your text has been generated.
You can preview it here too.
<audio controls>
# Modify the next line
<source src="${generated.url_for()}" type="audio/mpeg">
Your browser does not support playing audio.
</audio>
Press `Back` above if you want to modify the settings and generate a new file,
or click `Restart` below to begin a new request.
buttons:
- Exit: exit
- Restart: restart
To get the URL for a DAFIle, use the url_for method. This lets you have an address you can use for downloading or the web browser.
Conclusion
Congratulations! You are now ready to run the interview. Give it a go and see if you can download the audio of a text you would like spoken. (If you are still at the Playground, you can click “Save and Run” to ensure your work is safe and test it around a bit.)
This Text to Speech docassemble interview is relatively straightforward to me. Nevertheless, its simplicity also showcases several functions which you may want to be familiar with. Hopefully, you now have an idea of dealing with external services. If you manage to hook up something interesting, please share it with the community!
Bonus: Trapping errors and alerting the users
The code so far is enough to provide users with hours of fun (hopefully not at your expense). However, there are edge cases which you should consider if you plan to make your interview more widely available.
Firstly, while it's pretty clear in this tutorial that you should have updated your Configuration so that this interview can find your service account, this doesn't always happen for others. Admins might have overlooked it.
Add this code as the first mandatory code block of main.yml (before the one we wrote in Part 3):
mandatory: True
code: |
if get_config('google') is None or 'tts service account' not in get_config('google'):
if get_config('error notification email') is not None:
send_email(to=get_config('error notification email'),
subject='docassemble-Google TTS raised an error',
body='You need to set service account credentials in your google configuration.' )
else:
log('docassemble-Google TTS raised an error -- You need to set service account credentials in your google configuration.')
message('Error: No service account for Google TTS', 'Please contact your administrator.')
Take note that if you add more than one mandatory block, they are called in the order of their appearance in the interview file. So if you put this after the mandatory code block defining our processes, the process gets called before checking whether we should run this code in the first place.
This code block does a few things. Firstly it checks whether there is a “google” directive or a “tts service account” directive in the “google directive”. If it doesn't find any tts service account information, it checks whether the admin has set an error notification email in the Configuration. If it does, the server will send an email to the admin email to report the issue. If it doesn't, it prints the error on docassemble.log, one of the logs in the server. (If the admin doesn't check his email or logs, I am unsure how we can help the admin.)
This mandatory check before starting the interview is helpful to catch the most obvious error – no configuration. However, you can pass this check by putting nonsense in the “tts service account”. Google is not going to process this. There may be other errors, such as Google being offline.
Narrowing down every possible error will be very challenging. Instead, we will make one crucial check: the code did save a file at the end of the process. Even if we aren't going to be able to tell the user what went wrong, at least we spared the user the confusion of finding out that there was no file to download.
First, let's write the code that makes the check. Add this new code block.
event: file_check
code: |
path = generated.path()
if not os.path.exists(path):
if get_config('error notification email') is not None:
send_email(to=get_config('error notification email'),
subject='docassemble-Google TTS raised an error',
body='No file was saved in this interview.' )
else:
log('docassemble-Google TTS raised an error -- No audio file was saved in this interview.')
message('Error: No audio file was saved', 'We are not sure why. Please try again. If the problem persists, contact your administrator.')
This code checks whether the audio file (generated, a DAFile) is an actual file or an apparition. If it doesn't exist, the admin receives a message. The user is also alerted to the failure.
We would need to add a need directive to our results screen so that the check is made before the final screen to download the file is shown.
event: final_screen
need: # Add this line
- file_check # Add this line
question: |
Download your sound file **[here](${generated.url_for(attachment=True)}).**
subquestion: |
The audio on your text has been generated.
You can preview it here too.
<audio controls>
<source src="${generated.url_for()}" type="audio/mpeg">
Your browser does not support playing audio.
</audio>
Press `Back` above if you want to modify the settings and generate a new file,
or click `Restart` below to begin a new request.
buttons:
- Exit: exit
- Restart: restart
We would also need to import the python os standard library to make the check on our system. Add this new block near the top of our main.yml file.
imports:
- os.path
There you have it! The interview checks before you start whether there's a service account. It also checks before showing you the final screen whether your request succeeded and if an audio file is ready to download.
☝🏻Return to the overview of this tutorial.
#tutorial #Python #Programming #docassemble #Google #TTS #LegalTech

- Discuss... this Post
- If you found this post useful, or like my work, a tip is always appreciated:

- Follow this blog on the Fediverse [Enter the blog's address in Mastodon's search accounts function]
- Contact me:

 source:
source: 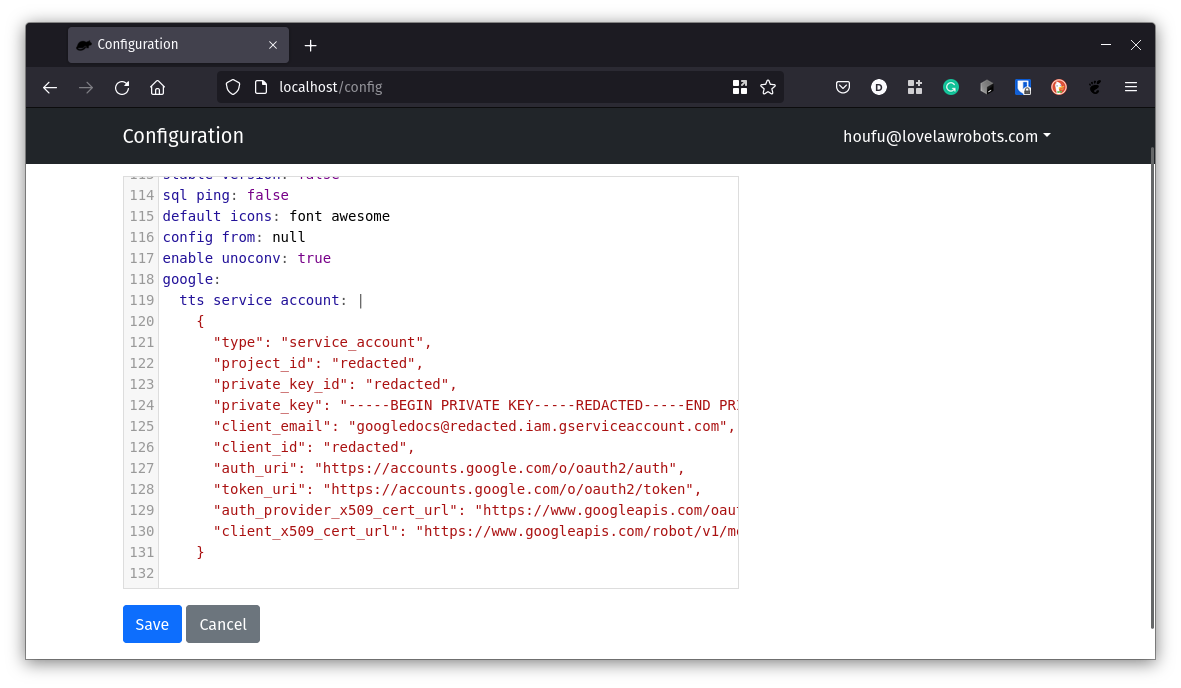 In this example, the lines you will add to the Configuration should look like lines 118 to 131.
In this example, the lines you will add to the Configuration should look like lines 118 to 131.