Christmas won't be here for a while
Houfu dreams of having his #MachineLearning tool for years but will still have to wait longer.
Houfu dreams of having his #MachineLearning tool for years but will still have to wait longer.
I’ve wanted to pen down my thoughts on the next stage of the evolution of my projects for some time. Here I go!
I had a lot of fun writing pdpc-decisions. It scraped data from the Personal Data Protection Commission’s enforcement decisions web page and produced a table, downloads and text. Now I got my copy of the database! From there, I made visualisations, analyses and fun graphs.
All for free.
The “free” includes the training I got coding in Python and trying out various stages of software development, from writing tests to distributing a package as a module and a docker container.
In the lofty “what’s next” section of the post, I wrote:
The ultimate goal of this code, however leads to my slow-going super-project, which I called zeeker. It’s a database of personal data protection resources in the cloud, and I hope to expand on the source material here to create an even richer database. So this will not be my last post on this topic.
I also believe that this is a code framework which can be used to scrape other types of legal cases like the Supreme Court, the State Court, or even the Strata Titles Board. However, given my interest in using enforcement decisions as a dataset, I started with PDPC first. Nevertheless, someone might find it helpful so if there is an interest, please let me know!
What has happened since then?
For one, personal data protection commission decisions are not interesting enough for me. Since working on that project, the deluge of decisions has trickled as the PDPC appeared to have changed its focus to compliance and other cool techy projects.
Furthermore, there are much more interesting data out there: for example, the PDPC has created many valuable guidelines which are currently unsearchable. As Singapore’s rules and regulations grow in complexity, there’s much hidden beneath the surface. The zeeker project shouldn’t just focus on a narrow area of law or judgements and decisions.
In terms of system architecture, I made two other decisions.
I grew more confident in my coding skills doing pdpc-decisions, but I used a few basic libraries and hacked my way through the data. When I look back at my code, it is unmaintainable. Any change can break the library, and the bog of whacked-up coding made it hard for me to understand what I was doing several months later. Tests, comments and other documentation help, but only if you’re a disciplined person. I’m not that kind of guy.
Besides writing code (which takes time and lots of motivation), I could also “piggyback” on the efforts of others to create a better stack. The stack I’ve decided so far has made coding more pleasant.
There are also other programs I would like to try — for example, I plan to deliver the data through an API, so I don’t need to use Python to code the front end. A Javascript framework like Next.JS would be more effective for developing websites.
Decoupling the project with the programming language also expands the palette of tools I can have. For example, instead of using a low-level Python library like pdfminer to “plumb” a PDF, I could use a self-hosted docker container like parsr to OCR or analyse the PDF and then convert it to text.
It’s about finding the best tool for the job, not depending only on my (mediocre) programming skills to bring results.
There’s, of course, an issue of technical debt (if parsr is not being developed anymore, my project can slow down as well). I think this is not so bad because all the projects I picked are open-source. I would also pick well-documented and popular projects to reduce this risk.
The only way the above is possible is a paradigm shift from making one single package of code to thinking about the work as a process. There are discrete parts to a task, and the code is suited for that particular task.
I was inspired to change the way I thought about zeeker when I saw the flow chart for OpenLaw NZ’s Data Pipeline.
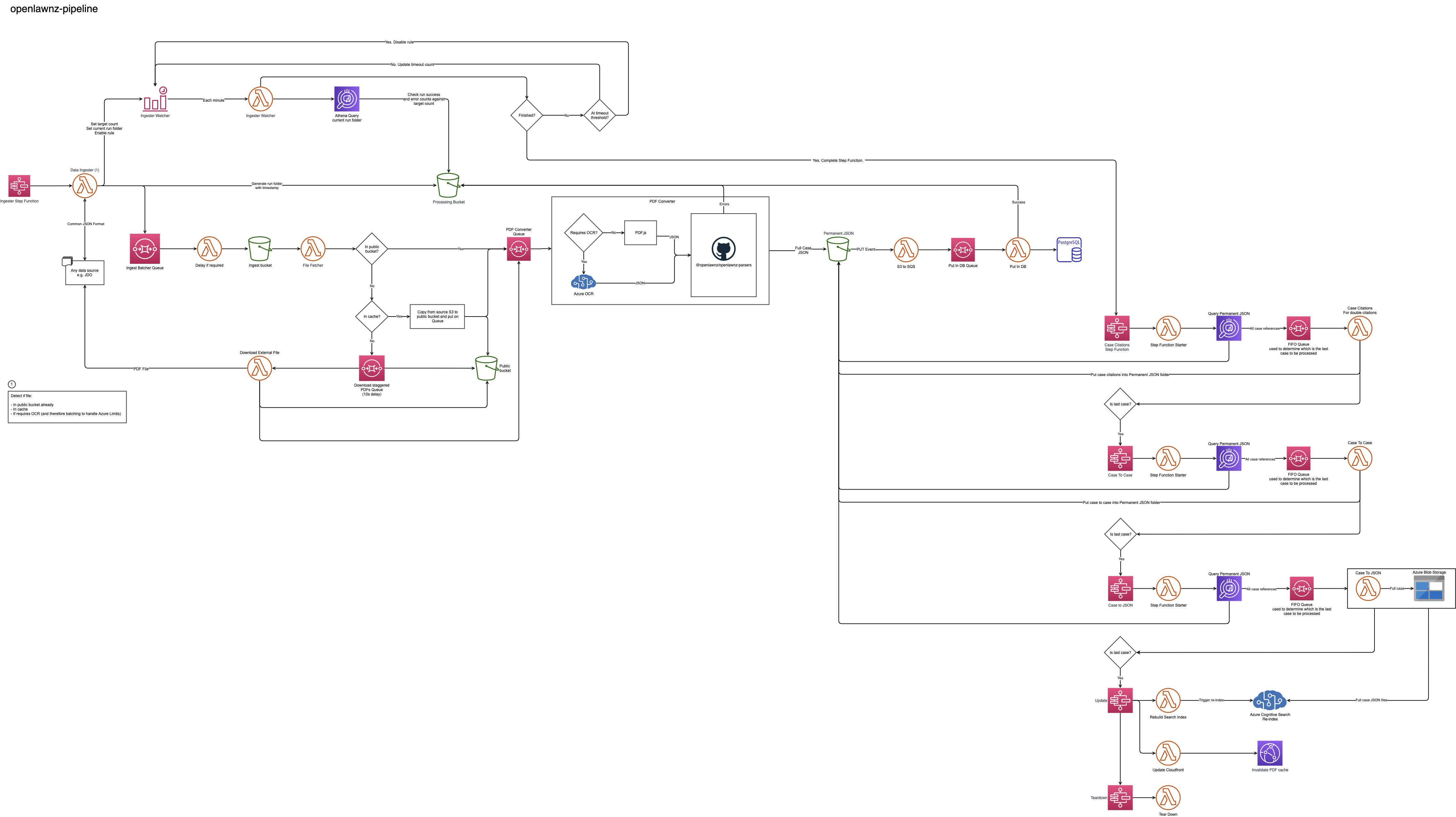 OpenLaw NZ’s data pipeline structure looks complicated, but it’s easy to follow for me!
OpenLaw NZ’s data pipeline structure looks complicated, but it’s easy to follow for me!
It’s made of several AWS components and services (with some Azure). The steps are small, like receiving an event, sending it to a serverless function, putting the data in an S3 bucket, and then running another serverless function.
The key insight is to avoid building a monolith. I am not committed to building a single program or website. Instead, a project is broken into smaller parts. Each part is only intended to do a small task well. In this instance, zeekerscrapers is only a scraper. It looks at the webpage, takes the information already present on the web page, and saves or downloads the information. It doesn't bother with machine learning, displaying the results or any other complicated processing.
Besides using the right tool for the job, it is also easier to maintain.
The modularity also makes it simple to chop and change for different types of data. For example, you need to OCR a scanned PDF but don’t need to do that for a digital PDF. If the workflow is a pipeline, you can take that task out of the pipeline. Furthermore, some tasks, such as downloading a file, are standard fare. If you have a code you can reuse over several pipelines, you can save much coding time.
On the other hand, I would be relying heavily on cloud infrastructure to accomplish this, which is by no means cheap or straightforward.

I have been quite busy lately, so I have yet to develop this at the pace I would like. For now, I have been converting pdpc-decisions to seeker. It’s been a breeze even though I took so much time.
On the other hand, my leisurely pace also allowed me to think about more significant issues, like what I can generalise and whether I will get bad vibes from this code in the future. Hopefully, the other scrapers can develop at breakneck speed once I complete thinking through the issues.
I have also felt more and more troubled by what to prioritise. Should I write more scrapers? Scrape what? Should I focus on adding more features to existing scrapers (like extracting entities and summarisation etc.)? When should I start writing the front end? When should I start advertising this project?
It’d be great to hear your comments. Meanwhile, keep watching this space!
#zeeker #Programming #PDPC-Decisions #Ideas #CloudComputing #LegalTech #OpenSource #scrapy #SQLModel #spaCy #WebScraping


Over the course of 2019 and 2020, I embarked on a quest to apply the new things I was learning in data science to my field of work in law.
The dataset I chose was the enforcement decisions from the Personal Data Protection Commission in Singapore. The reason I chose it was quite simple. I wanted a simple dataset covering a limited number of issues and is pretty much independent (not affected by stare decisis or extensive references to legislation or other cases). Furthermore, during that period, the PDPC was furiously issuing several decisions.
This experiment proved to be largely successful, and I learned a lot from the experience. This post gathers all that I have written on the subject at the time. I felt more confident to move on to more complicated datasets like the Supreme Court Decisions, which feature several of the same problems faced in the PDPC dataset.
Since then, the dataset has changed a lot, such as the website has changed, so your extraction methods would be different. I haven't really maintained the code, so they are not intended to create your own dataset and analysis today. However, techniques are still relevant, and I hope they still point you in a good direction.

The first step in any data science journey is to extract data from a source. In Singapore, one can find judgements from courts on websites for free. You can use such websites as the source of your data. API access is usually unavailable, so you have to look at the webpage to get your data.
It's still possible to download everything by clicking on it. However, you wouldn't be able to do this for an extended period of time. Automate the process by scraping it!

I used Python and Selenium to access the website and download the data I want. This included the actual judgement. Metadata, such as the hearing date etc., are also available conveniently from the website, so you should try and grab them simultaneously. In Automate Boring Stuff, I discussed my ideas on how to obtain such data.

Many judgements which are available online are usually in #PDF format. They look great on your screen but are very difficult for robots to process. You will have to transform this data into a format that you can use for natural language processing.
I took a lot of time on this as I wanted the judgements to read like a text. The raw text that most (free) PDF tools can provide you consists of joining up various text boxes the PDF tool can find. This worked all right for the most part, but if the text ran across the page, it would get mixed up with the headers and footers. Furthermore, the extraction revealed lines of text, not paragraphs. As such, additional work was required.
Firstly, I used regular expressions. This allowed me to detect unwanted data such as carriage returns, headers and footers in the raw text matched by the search term.
I then decided to use machine learning to train my computer to decide whether to keep a line or reject it. This required me to create a training dataset and tag which lines should be kept as the text. This was probably the fastest machine-learning exercise I ever came up with.
However, I didn't believe I was getting significant improvements from these methods. The final solution was actually fairly obvious. Using the formatting information of how the text boxes were laid out in the PDF , I could make reasonable conclusions about which text was a header or footer, a quote or a start of a paragraph. It was great!

With a dataset ready to be processed, I decided that I could finally use some of the cutting-edge libraries I have been raring to use, such as #spaCy and #HuggingFace.
One of the first experiments was to use spaCy's RuleMatcher to extract enforcement information from the summary provided by the authorities. As the summary was fairly formulaic, it was possible to extract whether the authorities imposed a penalty or the authority took other enforcement actions.
I also wanted to undertake key NLP tasks using my prepared data. This included tasks like Named Entity Recognition (does the sentence contain any special entities), summarisation (extract key points in the decision) and question answering (if you ask the machine a question, can it find the answer in the source?). To experiment, I used the default pipelines from Hugging Face to evaluate the results. There are clearly limitations, but very exciting as well!

Visualisations are very often the result of the data science journey. Extracting and processing data can be very rewarding, but you would like to show others how your work is also useful.
One of my first aims in 2019 was to show how PDPC decisions have been different since they were issued in 2016. Decisions became greater in number, more frequent, and shorter in length. There was clearly a shift and an intensifying of effort in enforcement.
I also wanted to visualise how the PDPC was referring to its own decisions. Such visualisation would allow one to see which decisions the PDPC was relying on to explain its decisions. This would definitely help to narrow down which decisions are worth reading in a deluge of information. As such, I created a network graph and visualised it. I called the result my “Star Map”.
Data continued to be very useful in leading the conclusion I made about the enforcement situation in Singapore. For example, how great an impact would the increase in maximum penalties in the latest amendments to the law have? Short answer: Probably not much, but they still have a symbolic effect.
As mentioned, I have been focusing on other priorities, so I haven't been working on PDPC-Decisions for a while. However, my next steps were:
Feel free to let me know if you have any comments!
#Features #PDPC-Decisions #PersonalDataProtectionAct #PersonalDataProtectionCommission #Decisions #Law #NaturalLanguageProcessing #PDFMiner #Programming #Python #spaCy #tech

This post is part of a series on my Data Science journey with PDPC Decisions. Check it out for more posts on visualisations, natural languge processing, data extraction and processing!
Avid followers of Love Law Robots will know that I have been hard at creating a corpus of Personal Data Protection Commission decisions. Downloading them and pre-processing them has taken a lot of work! However, it has managed to help me create interesting charts that shows insight at a macro level. How many decisions are released in a year and how long have they been? What decisions refer to each other in a network?
Unfortunately, what I would really to do is natural language processing. A robot should analyse text and make conclusions from it. This is much closer to the bread and butter of what lawyers do. I have been poking around spaCy, but using their regular expression function doesn’t really cut it.
This is not going to be the post where I say I trained a model to ask what the ratio decendi of a decision is. Part of the difficulty is finding a problem that is solvable given my current learning. So I have picked something that is useful and can be implemented fast.
The biggest problem I have is that the decisions, like many other judgements produced by Singapore courts, is in PDF. This looks great on paper but is gibberish to a computer. I explained this problem in an earlier post about pre-processing.
Having seen how the PDF extraction tool does its work, you can figure out which lines you want or don’t want. You don’t want empty lines. You don’t want lines with just numbers on them (these are usually page numbers). Citations? One-word indexes? The commissioner’s name. You can’t exactly think up of all the various permutations and then brainstorm on regular expression rules to cover all of them.
It becomes a whack a mole.
It was during one of those rage-filled “how many more things do I have to do to improve this” nights when it hit me.
“I know what lines I do not want to keep. Why don’t I just tell the computer what they are instead of abstracting the problem with regular expressions?!”
Then I suddenly remembered about machine learning. Statistically, the robot, after learning about what lines I would keep or not, could make a guess. If the robot can guess right most of the time, that would determine in which cases regular expression must be used.
So, I got off my chair, selected dozens of PDFs and converted them into text. Then I separated the text into a CSV file and started classifying them.
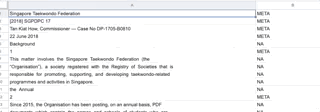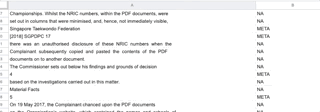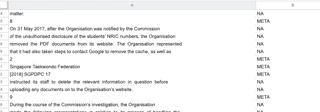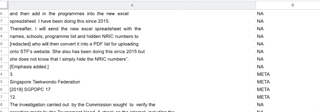 Classification of lines for training
Classification of lines for training
I managed to compile a list of over five thousand lines for my training and test data. After that, I lifted the training code from spaCy’s documentation to train the model. My Macbook Pro’s fans got noisy, but it was done in a matter of minutes.
Asking the model to classify sentences gave me the following results:
| Text | Remove or Keep |
|---|---|
| Hello. | Keep |
| Regulation 10(2) provides that a contract referred to in regulation 10(1) must: | Keep |
| YEONG ZEE KIN | Remove |
| [2019] SGPDPC 18 | Remove |
| transferred under the contract”. | Keep |
| There were various internal frameworks, policies and standards which apply to | Keep |
| (vi) | Remove |
By applying it to text extracted from the PDF, we can get a resulting document which can be used in the corpus. You can check out the code used for this in the Github Repository under the branch “line_categoriser”.
Will I use this for production purposes? Nope. When I ran some decisions through this process, the effectiveness is unfortunately like using regular expressions. The model, which weighs nearly 19Mbs, also took noticeably longer to process a series of strings.
My current thoughts on this specific problem is for a different approach. It would involve studying PDF internals and observing things like font size and styles to determine whether a line is a header or a footnote. It would also make it easier to join lines of the same style to make a paragraph. Unfortunately, that is some homework for another day.
Was it a wasted adventure? I do not think so. Ultimately, I wanted to experiment, and embarking on a task I could do in a week of nights was surely insightful in determining whether I can do it, and what are the limitations of machine learning in certain tasks.
So, hold on to your horses, I will be getting there much sooner now.
#PDPC-Decisions #spaCy #NaturalLanguageProcessing

This post is part of a series on my Data Science journey with PDPC Decisions. Check it out for more posts on visualisations, natural languge processing, data extraction and processing!
As mentioned in my previous post, I have not been able to spend time writing as much code as I wanted. I had to rewrite a lot of code due to the layout change in the PDPC Website. That was not the post I wanted to write. I have finally been able to write about my newest forays for this project.
I had noticed that the summary provided by the Personal Data Protection Commission provided an easy place to cull basic information. So, I have added enforcement information. Decisions now tell you whether a financial penalty or a warning was meted out.
Information is extracted from the summaries using RuleMatcher in spaCy. It isn’t perfect. Some text does not really fit the mould. However, due to the way the summaries are written, information is mostly extracted accurately.
 Visualising the parts of speech in a typical sentence can allow you to write rules to extract information.
Visualising the parts of speech in a typical sentence can allow you to write rules to extract information.
This is the first time I have used spaCy or any natural language processing for this purpose. Remarkably, it has been fast. Culling this information (as well as the other extra features) only added about two hundred seconds to building a database from scratch. I would like to find more avenues to use these newfound techniques!
Court decisions are special in that they often require references to leading cases. This is because they are either binding (stare decisis) or persuasive to the decision maker. Of course, previous PDPC Decisions are not binding on the PDPC. Lately, respondents have been referring to the body of cases to argue they should be treated alike. I have not read a decision where this argument has worked.
Nevertheless, the network of cases referring to and referred by offers remarkably interesting insights. To imagine, we are looking at a social network of cases. To establish a point, the Personal Data Protection Commission does refer to earlier cases. All things being equal, a case with more references is more influential.
pdpc-decisions now reads the text of the decisions to create a list of decisions it refers to in the decision (“ referring to “). From the list of decisions, we can also create a list of decisions which makes references to it (“ referred by “). Because of the haphazard way the PDPC has been writing its decisions and its citations, this is also not perfect, but it is still kind of accurate.
As I mentioned, compiling a network of decisions can offer some interesting insights. So here it is — the social network of PDPC decisions.
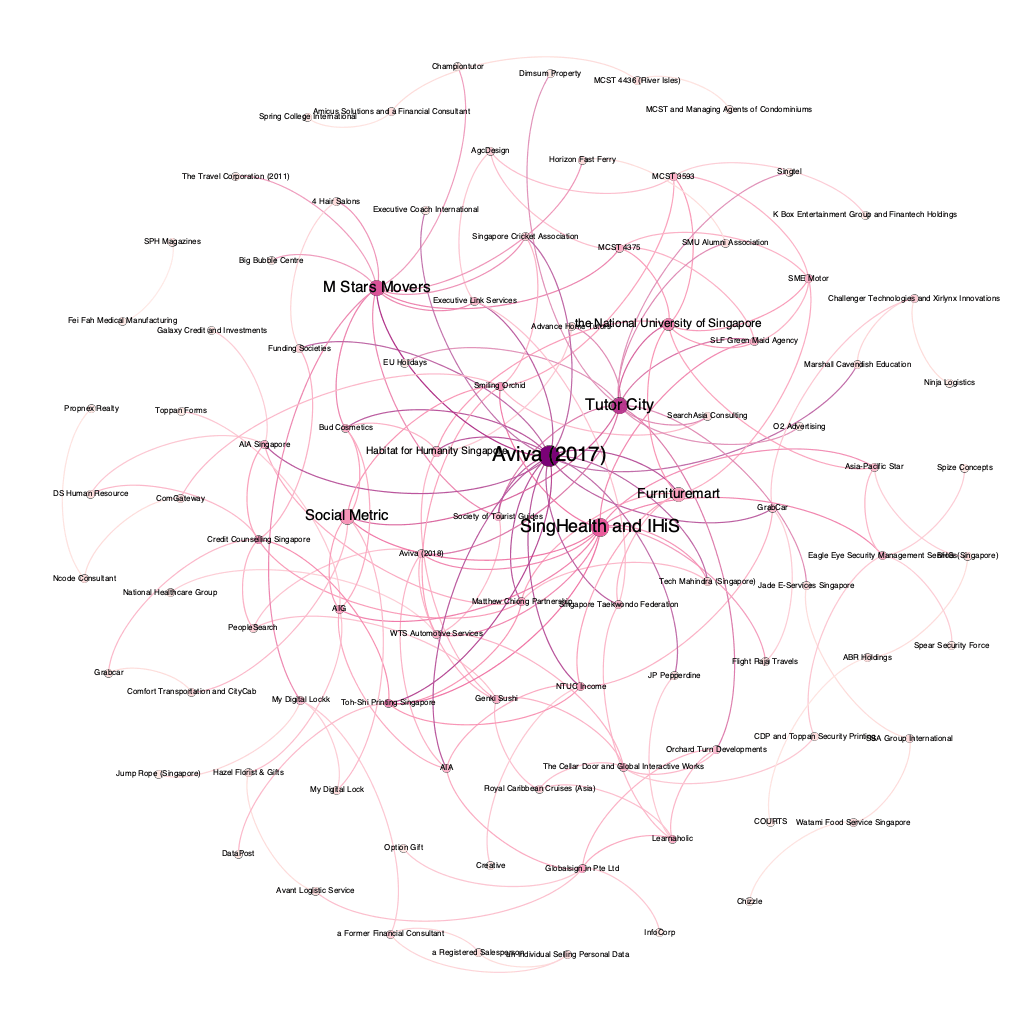 I guess this is the real pdpc decisions in one chart…
I guess this is the real pdpc decisions in one chart…
Update (24/4/2020): The chart was lumping together the Aviva case in 2018 with the Aviva case in 2017. The graph has been updated. Not much has changed in the big picture though.
Of course, a more advanced visualisation tool would allow you to drill down to see which cases are more influential. However, a big diagram like the above shows you which are the big boys in this social network.
Before I leave this section, here’s a fun fact to take home. Based on the computer’s analysis, over 68% of PDPC decisions refer to one another. That’s a lot of chatter!
I keep thinking I have finished my work here, but there seems to be new things coming up. Here is some interesting information I would like to find out:
You would just have to keep watching this space! What kind of information is interesting to you too?
#PDPC-Decisions #NaturalLanguageProcessing #spaCy


 Love.Law.Robots.Houfu
Love.Law.Robots.Houfu
 GitHubhoufu
GitHubhoufu