Introducing: zeekerscrapers

I’ve wanted to pen down my thoughts on the next stage of the evolution of my projects for some time. Here I go!
What’s next after pdpc-decisions?
I had a lot of fun writing pdpc-decisions. It scraped data from the Personal Data Protection Commission’s enforcement decisions web page and produced a table, downloads and text. Now I got my copy of the database! From there, I made visualisations, analyses and fun graphs.
All for free.
The “free” includes the training I got coding in Python and trying out various stages of software development, from writing tests to distributing a package as a module and a docker container.
In the lofty “what’s next” section of the post, I wrote:
The ultimate goal of this code, however leads to my slow-going super-project, which I called zeeker. It’s a database of personal data protection resources in the cloud, and I hope to expand on the source material here to create an even richer database. So this will not be my last post on this topic.
I also believe that this is a code framework which can be used to scrape other types of legal cases like the Supreme Court, the State Court, or even the Strata Titles Board. However, given my interest in using enforcement decisions as a dataset, I started with PDPC first. Nevertheless, someone might find it helpful so if there is an interest, please let me know!
What has happened since then?
For one, personal data protection commission decisions are not interesting enough for me. Since working on that project, the deluge of decisions has trickled as the PDPC appeared to have changed its focus to compliance and other cool techy projects.
Furthermore, there are much more interesting data out there: for example, the PDPC has created many valuable guidelines which are currently unsearchable. As Singapore’s rules and regulations grow in complexity, there’s much hidden beneath the surface. The zeeker project shouldn’t just focus on a narrow area of law or judgements and decisions.
In terms of system architecture, I made two other decisions.
Use more open-source libraries, and code less.
I grew more confident in my coding skills doing pdpc-decisions, but I used a few basic libraries and hacked my way through the data. When I look back at my code, it is unmaintainable. Any change can break the library, and the bog of whacked-up coding made it hard for me to understand what I was doing several months later. Tests, comments and other documentation help, but only if you’re a disciplined person. I’m not that kind of guy.
Besides writing code (which takes time and lots of motivation), I could also “piggyback” on the efforts of others to create a better stack. The stack I’ve decided so far has made coding more pleasant.
There are also other programs I would like to try — for example, I plan to deliver the data through an API, so I don’t need to use Python to code the front end. A Javascript framework like Next.JS would be more effective for developing websites.
Decoupling the project with the programming language also expands the palette of tools I can have. For example, instead of using a low-level Python library like pdfminer to “plumb” a PDF, I could use a self-hosted docker container like parsr to OCR or analyse the PDF and then convert it to text.
It’s about finding the best tool for the job, not depending only on my (mediocre) programming skills to bring results.
There’s, of course, an issue of technical debt (if parsr is not being developed anymore, my project can slow down as well). I think this is not so bad because all the projects I picked are open-source. I would also pick well-documented and popular projects to reduce this risk.
It’s all a pipeline, baby.
The only way the above is possible is a paradigm shift from making one single package of code to thinking about the work as a process. There are discrete parts to a task, and the code is suited for that particular task.
I was inspired to change the way I thought about zeeker when I saw the flow chart for OpenLaw NZ’s Data Pipeline.
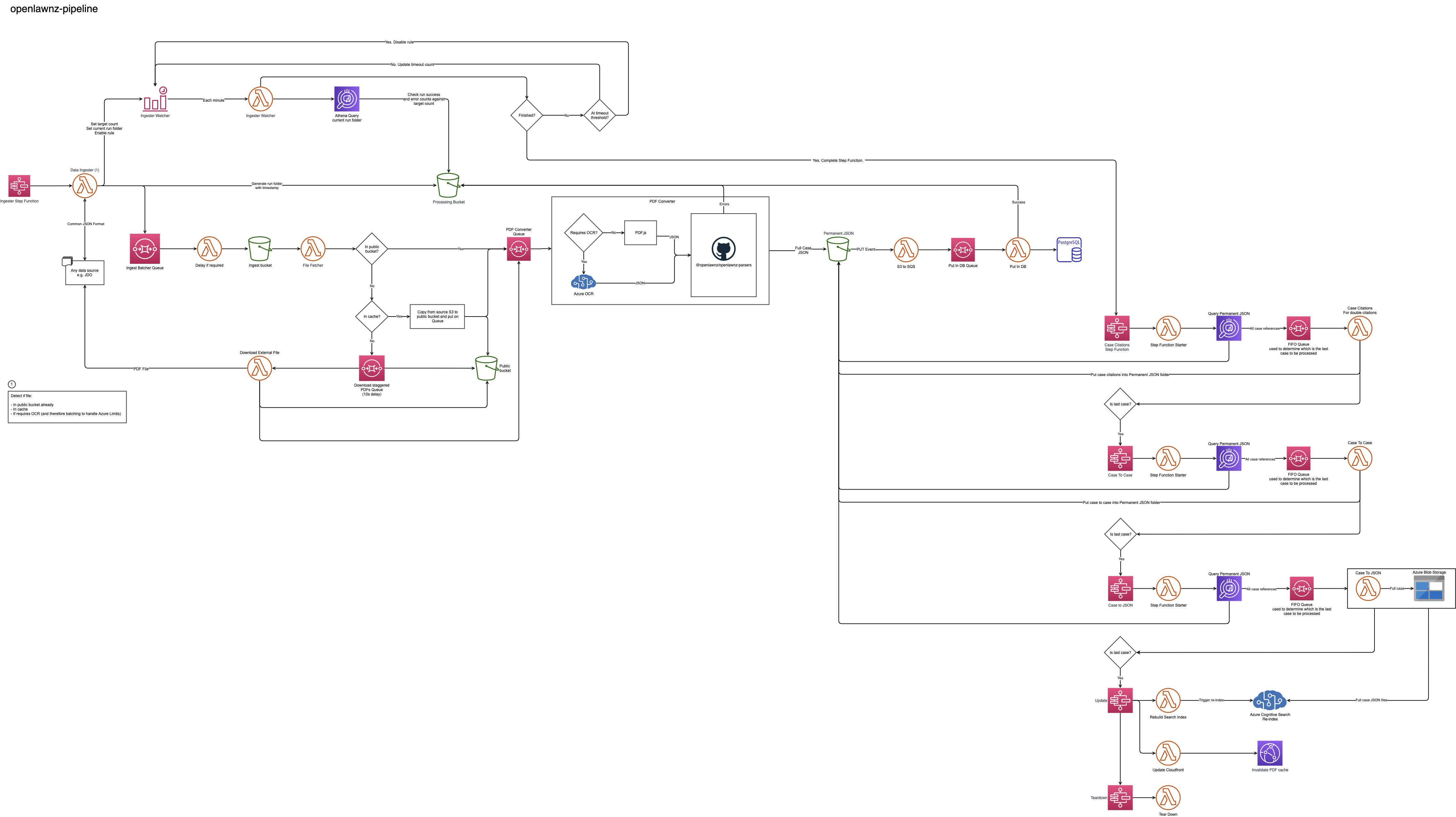 OpenLaw NZ’s data pipeline structure looks complicated, but it’s easy to follow for me!
OpenLaw NZ’s data pipeline structure looks complicated, but it’s easy to follow for me!
It’s made of several AWS components and services (with some Azure). The steps are small, like receiving an event, sending it to a serverless function, putting the data in an S3 bucket, and then running another serverless function.
The key insight is to avoid building a monolith. I am not committed to building a single program or website. Instead, a project is broken into smaller parts. Each part is only intended to do a small task well. In this instance, zeekerscrapers is only a scraper. It looks at the webpage, takes the information already present on the web page, and saves or downloads the information. It doesn't bother with machine learning, displaying the results or any other complicated processing.
Besides using the right tool for the job, it is also easier to maintain.
The modularity also makes it simple to chop and change for different types of data. For example, you need to OCR a scanned PDF but don’t need to do that for a digital PDF. If the workflow is a pipeline, you can take that task out of the pipeline. Furthermore, some tasks, such as downloading a file, are standard fare. If you have a code you can reuse over several pipelines, you can save much coding time.
On the other hand, I would be relying heavily on cloud infrastructure to accomplish this, which is by no means cheap or straightforward.
Experiments continue

I have been quite busy lately, so I have yet to develop this at the pace I would like. For now, I have been converting pdpc-decisions to seeker. It’s been a breeze even though I took so much time.
On the other hand, my leisurely pace also allowed me to think about more significant issues, like what I can generalise and whether I will get bad vibes from this code in the future. Hopefully, the other scrapers can develop at breakneck speed once I complete thinking through the issues.
I have also felt more and more troubled by what to prioritise. Should I write more scrapers? Scrape what? Should I focus on adding more features to existing scrapers (like extracting entities and summarisation etc.)? When should I start writing the front end? When should I start advertising this project?
It’d be great to hear your comments. Meanwhile, keep watching this space!
#zeeker #Programming #PDPC-Decisions #Ideas #CloudComputing #LegalTech #OpenSource #scrapy #SQLModel #spaCy #WebScraping

- Discuss... this Post
- If you found this post useful, or like my work, a tip is always appreciated:

- Follow this blog on the Fediverse [Enter the blog's address in Mastodon's search accounts function]
- Contact me:


 GitHubhoufu
GitHubhoufu

 Love.Law.Robots.Houfu
Love.Law.Robots.Houfu Photo by
Photo by  PDPC Logo
PDPC Logo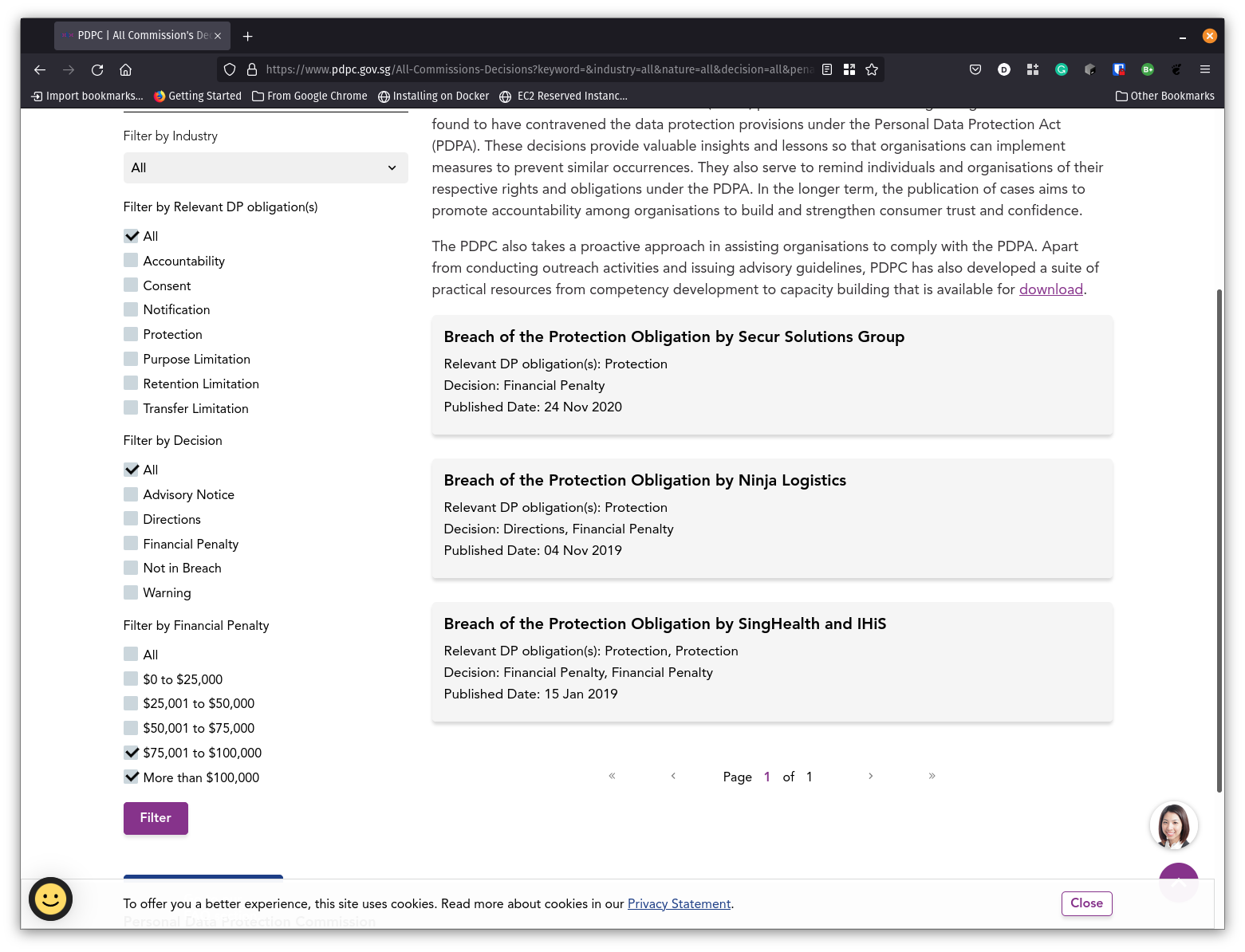 The top of the financial penalty list (As of November 2021). Take note of the financial penalty filters at the bottom left corner.
The top of the financial penalty list (As of November 2021). Take note of the financial penalty filters at the bottom left corner. Photo by
Photo by  Photo by
Photo by  Photo by
Photo by  Automate Boring Stuff: Get Python and your Web Browser to download your judgements
Automate Boring Stuff: Get Python and your Web Browser to download your judgements Photo by
Photo by  Photo by
Photo by  Photo by
Photo by 
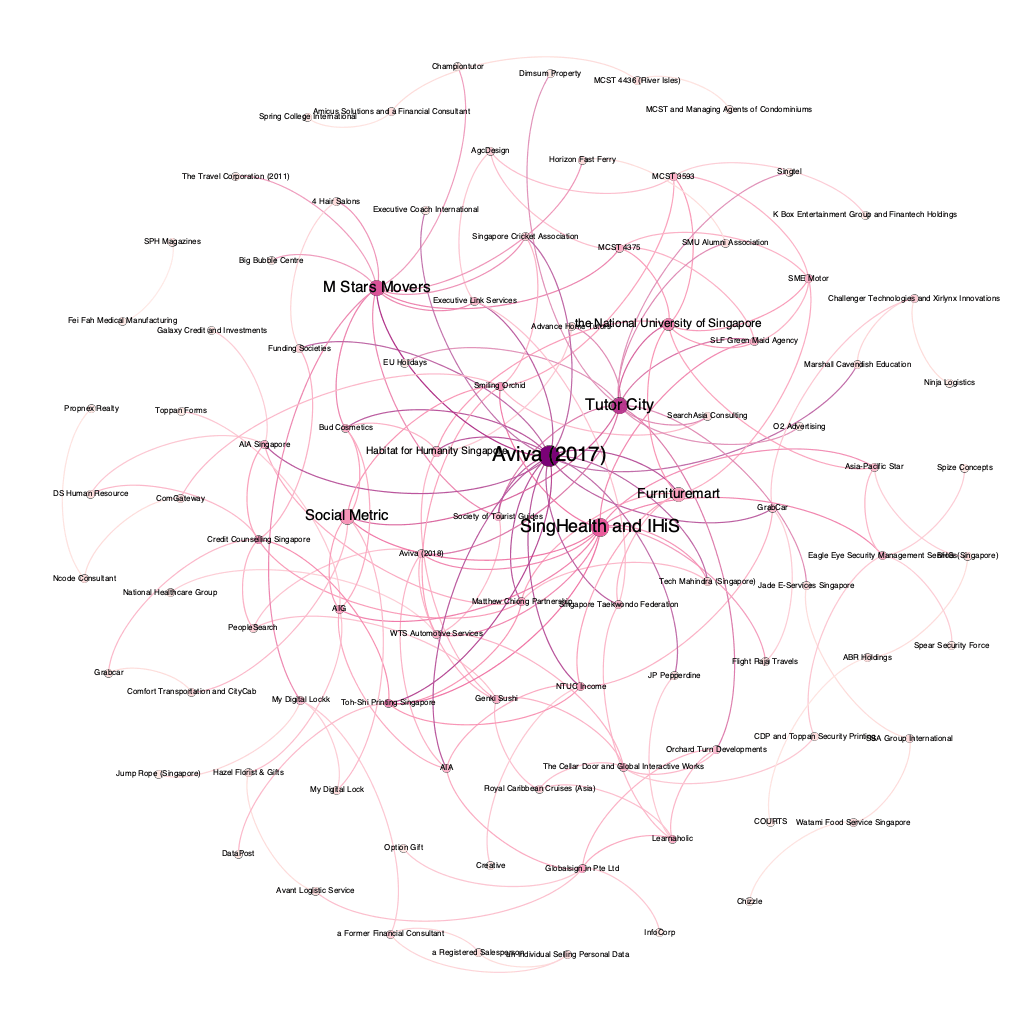
 The first version of the star map.
The first version of the star map.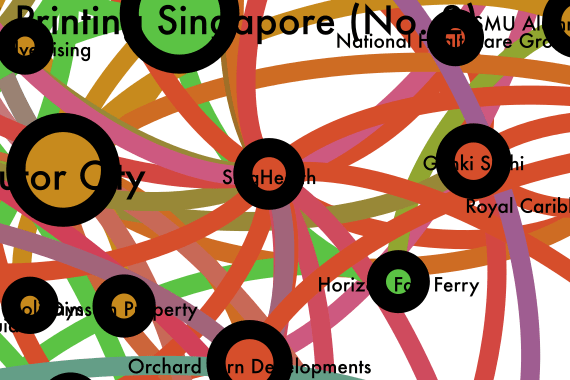 Location of SingHealth decision on the star map.
Location of SingHealth decision on the star map.
 Useful layout information to analyse the structure of a PDF.
Useful layout information to analyse the structure of a PDF.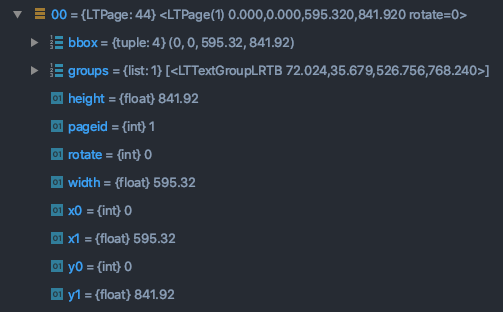 The properties of a LTPage reveal its layout information.
The properties of a LTPage reveal its layout information.

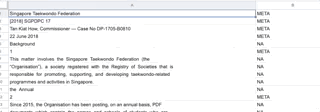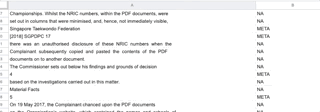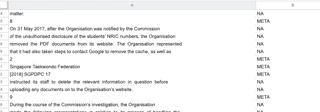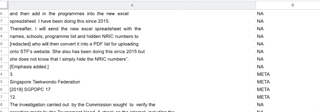 Classification of lines for training
Classification of lines for training GitHubhoufu
GitHubhoufu
 Visualising the parts of speech in a typical sentence can allow you to write rules to extract information.
Visualising the parts of speech in a typical sentence can allow you to write rules to extract information.
 I guess this is the
I guess this is the 

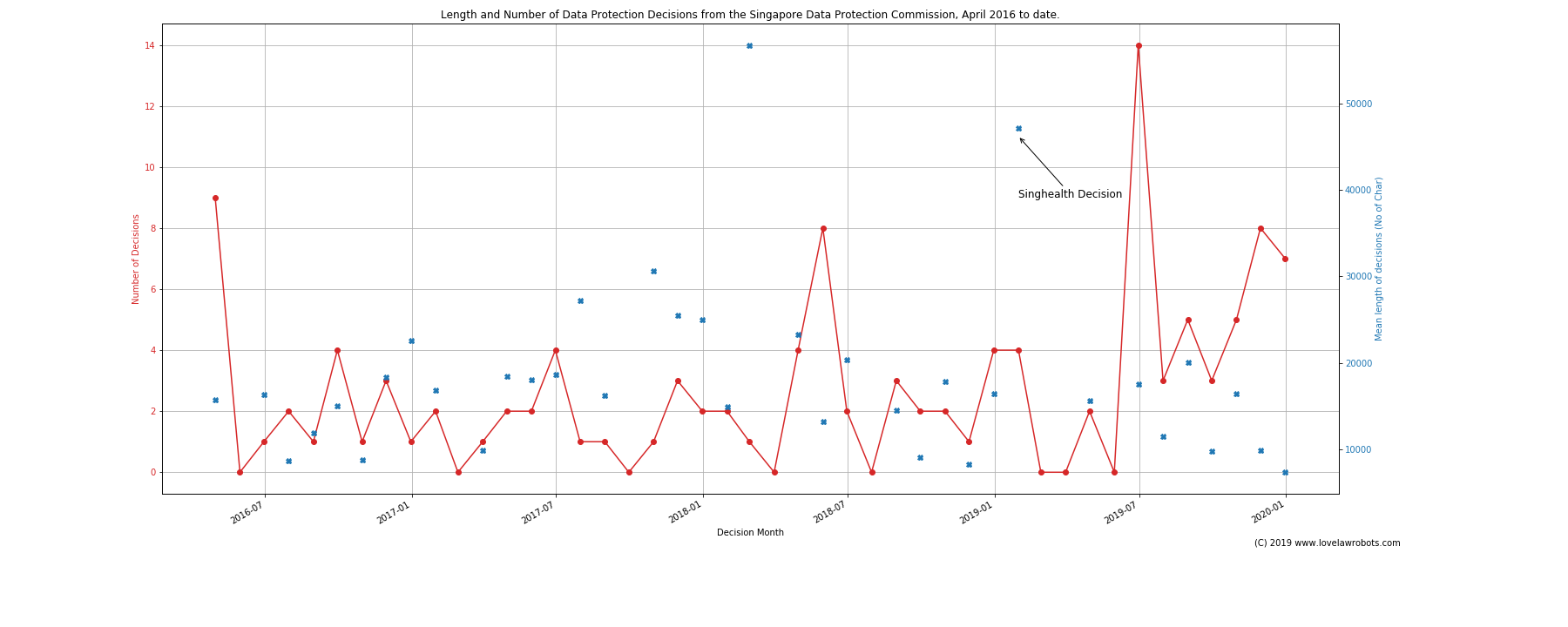 Show the number and average length of PDPC Decisions since April 2016
Show the number and average length of PDPC Decisions since April 2016