
This post is part of a series on my Data Science journey with PDPC Decisions. Check it out for more posts on visualisations, natural languge processing, data extraction and processing!
Update 13 June 2020: “At least until the PDPC breaks its website.” How prescient… about three months after I wrote this post, the structure of the PDPC’s website was drastically altered. The concepts and the ideas in this post haven’t changed, but the examples are outdated. This gives me a chance to rewrite this post. If I ever get round to it, I’ll provide a link.
Regular readers would already know that I try to run a github repository which tries to compile all personal data protection decisions in Singapore. Decisions are useful resources teeming with lots of information. They have statistics, insights into what factors are relevant in decision making and show that data protection is effective in Singapore. Even basic statistics about decisions make newspaper stories here locally. It would be great if there was a way to mine all that information!
houfu/pdpc-decisionsData Protection Enforcement Cases in Singapore. Contribute to houfu/pdpc-decisions development by creating an account on GitHub. GitHubhoufu
GitHubhoufu
Unfortunately, using the Personal Data Protection Commission in Singapore’s website to download judgements can be painful.
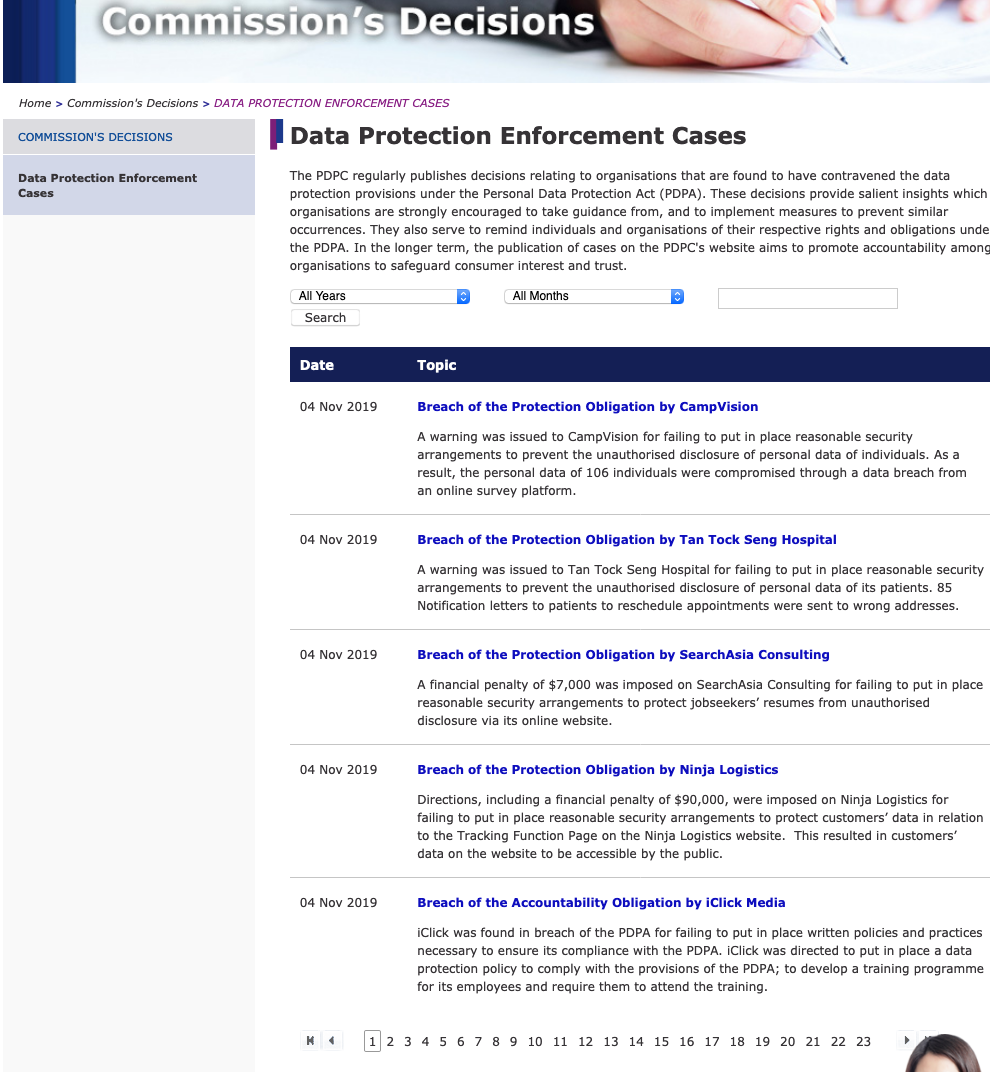 This is our target webpage today – Note the website has been transformed.
This is our target webpage today – Note the website has been transformed.
As you can see, you are only able to view no more than 5 decisions at one time. As the first decision dates back to 2016, you will have to go through several pages to grab everything! Actually just 23. I am sure you can do all that in 1 night, right? Right?
If you are not inclined to do it, then get your computer to do it. Using selenium, I wrote a python script to automate the whole process of finding all the decisions available on the website. What could have been a tedious night’s work was accomplished in 34 seconds.
Check out the script here.
What follows here is a step by step write up of how I did it. So hang on tight!
Section 1: Observe your quarry
Before setting your computer loose on a web page, it pays to understand the structure and inner workings of your web page. Open this up by using your favourite browser. For Chrome, this is Developer's Tools and in Firefox, this is Web Developer. You will be looking for a tab called Sources, which shows you the HTML code of the web page.
Play with the structure of the web page by hovering over various elements of the web page with your mouse. You can then look for the exact elements you need to perform your task:
- In order to see a new page, you will have to click on the page number in the pagination. This is under a section (a CSS class) called
group__pages. Each page-number is under a section (another CSS class) called page-number.
- Each decision has its own section (a CSS class) named
press-item. The link to the download, which is either to a text file or a PDF file, is located in a link in each press-item.
- Notice too that each
press-item also has other metadata regarding the decision. For now, we are curious about the date of the decision and the respondent.
Section 2: Decide on a strategy
Having figured out the website, you can decide on how to achieve your goal. In this case, it would be pretty similar to what you would have done manually.
- Start on a page
- Click on a link to download
- Go to the next link until there are no more links
- Move on to the next page
- Keep repeating steps 1 to 4 until there are no more pages
- Profit!
Since we did notice the metadata, let’s use it. If you don’t use what is already in front of you, you will have to read the decision to extract such information In fact, we are going to use the metadata to name our decision.
Section 3: Get your selenium on it!
Selenium drives a web browser. It mimics user interactions on the web browser, so our strategy in Step 2 is straightforward to implement. Instead of moving our mouse like we ordinarily would, we would tell the web driver what to do instead.
WebDriver :: Documentation for SeleniumDocumentation for Selenium Selenium
Selenium
Let’s translate our strategy to actual code.
Step 1: Start on a page
We are going to need to start our web driver and get it to run on our web page.
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
PDPCdecisionssite = “https://www.pdpc.gov.sg/Commissions-Decisions/Data-Protection-Enforcement-Cases"
# Setup webdriver
options = Options()
# Uncomment the next two lines for a headless chrome
# options.addargument('—headless')
# options.addargument('—disable-gpu')
# options.addargument('—window-size=1920,1080')
driver = Chrome(options=options)
driver.get(PDPCdecisions_site)
Steps 2: Download the file
Now that you have prepared your page, let’s drill down to the individual decisions itself. As we figured out earlier, each decision is found in a section named press-item. Get selenium to collect all the decisions on the page.
judgements = driver.findelementsbyclassname('press-item')
Recall that we were not just going to download the file, we will also be using the date of the decision and the respondent to name the file. For the date function, I found out that under each press-item there is a press-date which gives us the text of the decision date; we can easily convert this to a python datetime so we can format it anyway we like.
def getdate(item: WebElement):
itemdate = datetime.strptime(item.findelementbyclassname('press_date').text, “%d %b %Y”)
return itemdate.strftime(“%Y-%m-%d”)
For the respondent, the heading (which is written in a fixed format and also happens to be the link to the download – score!) already gives you the information. Use a regular expression on the text of the link to suss it out. (One of the decisions do not follow the format of “Breach … by respondent “, so the alternative is also laid out)
def get_respondent(item):
text = item.text
return re.split(r”\s+[bB]y|[Aa]gainst\s+“, text, re.I)[1]
You are now ready to download a file! Using the metadata and the link you just found, you can come up with meaningful names to download your files. Naming your own files will also help you avoid the idiosyncratic ways the PDPC names its own downloads.
Note that some of the files are not PDF downloads but instead are short texts in web pages. Using the earlier strategies, you can figure out what information you need. This time, I used BeautifulSoup to get the information. I did not want to use selenium to do any unnecessary navigation. Treat PDFs and web pages differently.
def downloadfile(item, filedate, filerespondent):
url = item.getproperty('href')
print(“Downloading a File: “, url)
print(“Date of Decision: “, filedate)
print(“Respondent: “, filerespondent)
if url[-3:] == 'pdf':
dest = SOURCEFILEPATH + filedate + ' ' + filerespondent + '.pdf'
wget.download(url, out=dest)
else:
with open(SOURCEFILEPATH + filedate + ' ' + filerespondent + '.txt', “w”) as f:
from bs4 import BeautifulSoup
from urllib.request import urlopen
soup = BeautifulSoup(urlopen(url), 'html5lib')
text = soup.find('div', class_='rte').getText()
lines = re.split(r”ns+“, text)
f.writelines([line + 'n' for line in lines if line != “”])
Steps 3 to 5: Download every item on every page
The next steps follow a simple idiom — for every page and for every item on each page, download a file.
for pagecount in range(len(pages)):
pages[pagecount].click()
print(“Now at Page “, pagecount)
pages = refreshpages(driver)
judgements = driver.findelementsbyclassname('press-item')
for judgement in judgements:
date = getdate(judgement)
link = judgement.findelementbytagname('a')
respondent = getrespondent(link)
download_file(link, date, respondent)
Unfortunately, once selenium changes a page, it needs to be refreshed. We are going to need a new group__pages and page-number in order to continue accessing the page. I wrote a function to “refresh” the variables I am using to access these sections.
def refreshpages(webdriver: Chrome):
grouppages = webdriver.findelementbyclassname('group_pages')
return grouppages.findelementsbyclassname('page-number')
. . .
pages = refresh_pages(driver)
Conclusion
Once you got your web driver to be thorough, you are done! In my last pass, 115 decisions were downloaded in 34 seconds. The best part is that you can repeat this any time there are new decisions. Data acquisition made easy! At least until the PDPC breaks its website.
Postscript: Is this… Illegal?
 I’m listening…
I’m listening…
Web scraping has always been quite controversial and the stakes can be quite high. Copyright infringement, Misuse of Computer Act and trespass, to name a few. Funnily enough, manually downloading may be less illegal than using a computer. The PDPC’s own terms of use is not on point at this.
( Update 15 Mar 2021 : OK I think I am being fairly obtuse about this. There is a paragraph that states you can’t use robots or spiders to monitor their website. That might make sense in the past when data transfers were expensive, but I don't think that this kind of activity at my scale can crash a server.)
Personally, I feel this particular activity is fairly harmless — this is considered “own personal, non-commercial use” to me. I would likely continue with this for as long as I would like my own collection of decisions. Or until they provide better programmatic access to their resources.
Ready to mine free online legal materials in Singapore? Not so fast!Amendments to Copyright Act might support better access to free online legal materials in Singapore by robots. I survey government websites to find out how friendly they are to this. Love.Law.Robots.Houfu
Love.Law.Robots.Houfu In 2021, the Copyright Act in Singapore was amended to support data analysis, like web scraping? I wrote this follow-up post.
In 2021, the Copyright Act in Singapore was amended to support data analysis, like web scraping? I wrote this follow-up post.
#PDPC-Decisions #Programming #Python #tutorial #Updated
 Love.Law.Robots. – A blog by Ang Hou Fu
Love.Law.Robots. – A blog by Ang Hou Fu
- Discuss... this Post
- If you found this post useful, or like my work, a tip is always appreciated:

- Follow this blog on the Fediverse [Enter the blog's address in Mastodon's search accounts function]
- Contact me:


 Pi-hole logotelekrmor
Pi-hole logotelekrmor
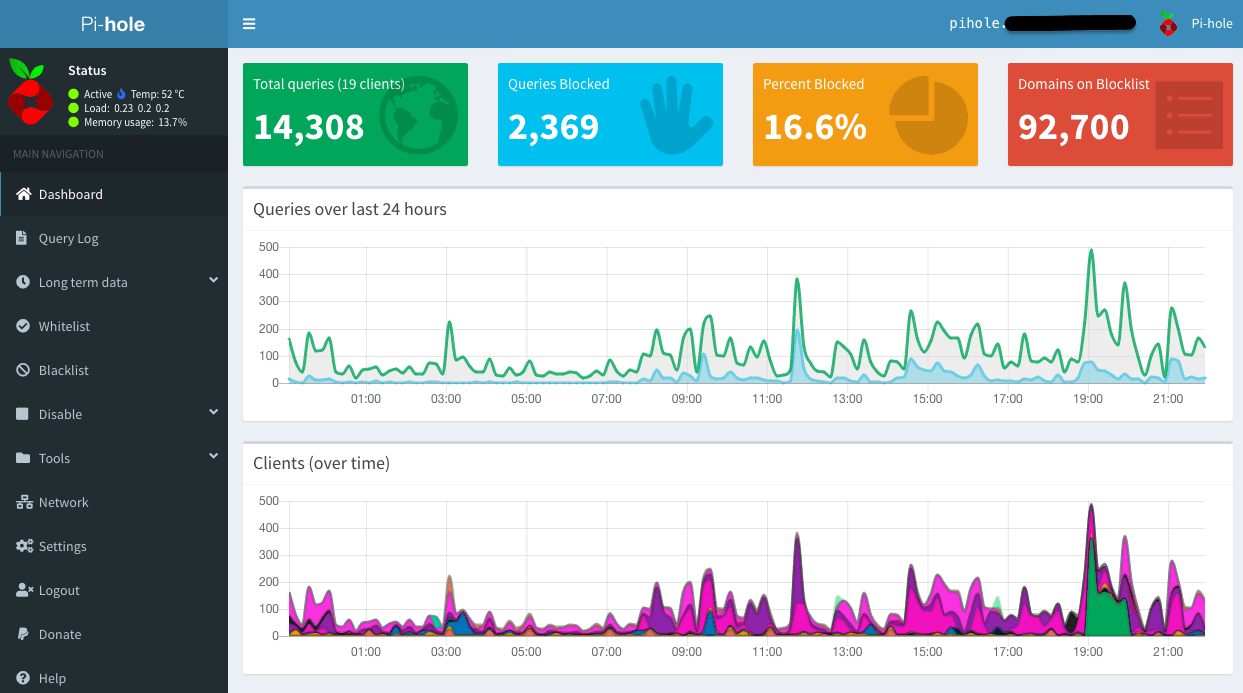 So many queries, so many blocked. ( Update 11/5/20 : Screenshot updated to show the new version 5.0 interface. So many bars now!)
So many queries, so many blocked. ( Update 11/5/20 : Screenshot updated to show the new version 5.0 interface. So many bars now!)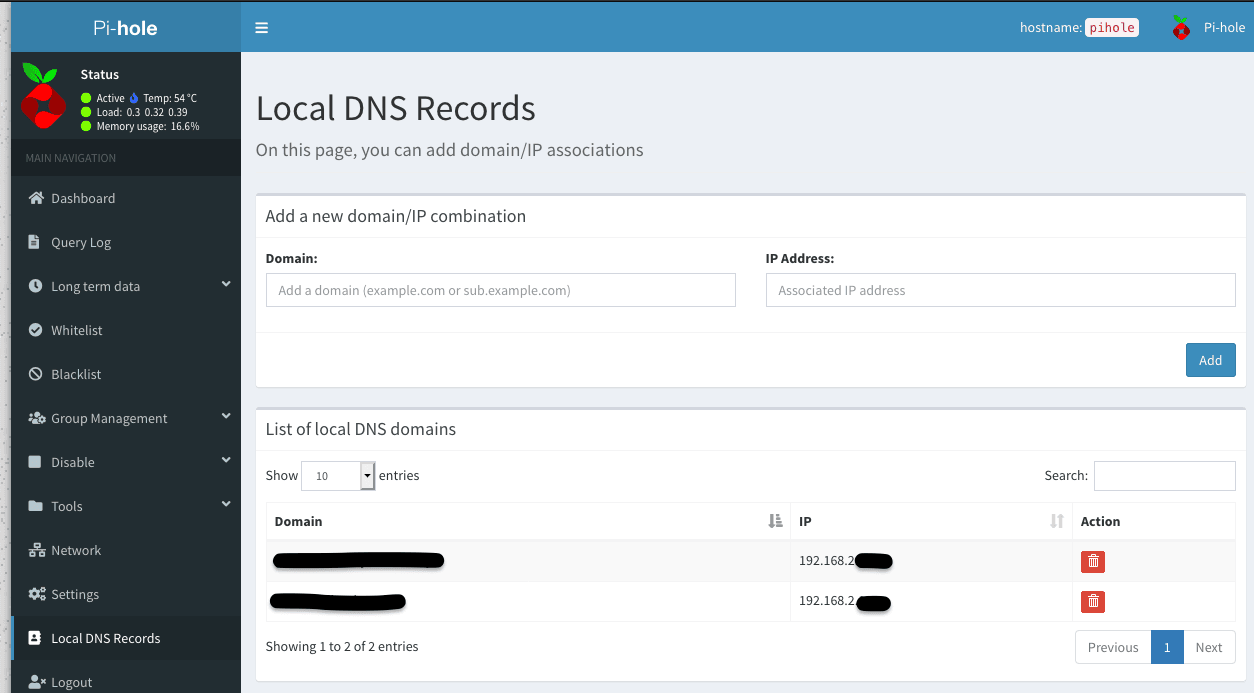 The dashboard used to add local DNS domains. New in version 5.0.
The dashboard used to add local DNS domains. New in version 5.0. Traefik Labs: Makes Networking Boring
Traefik Labs: Makes Networking Boring


